Evals with Real Examples and DeepEval: A Student-Friendly Classroom Guide
Why Evals Matter: The Exam Paper for LLM Apps
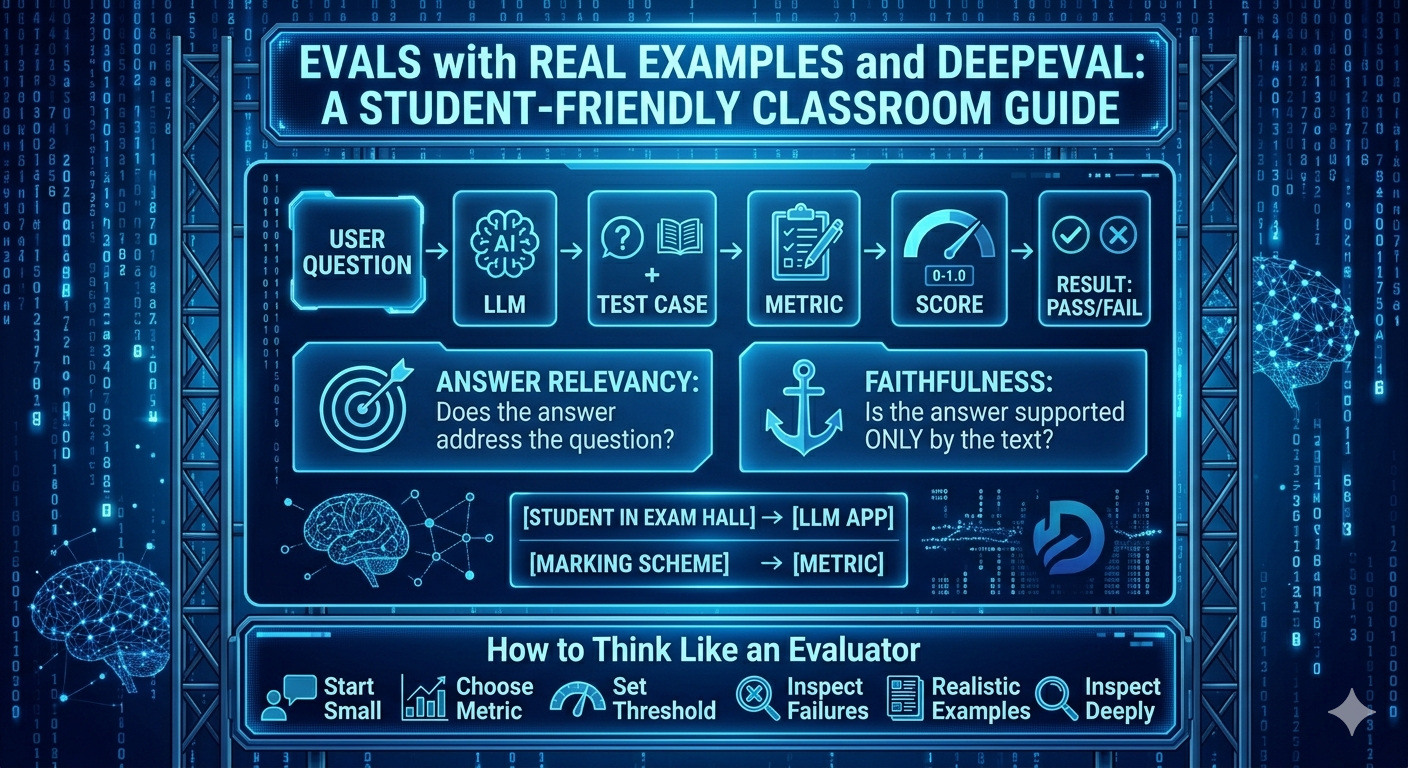
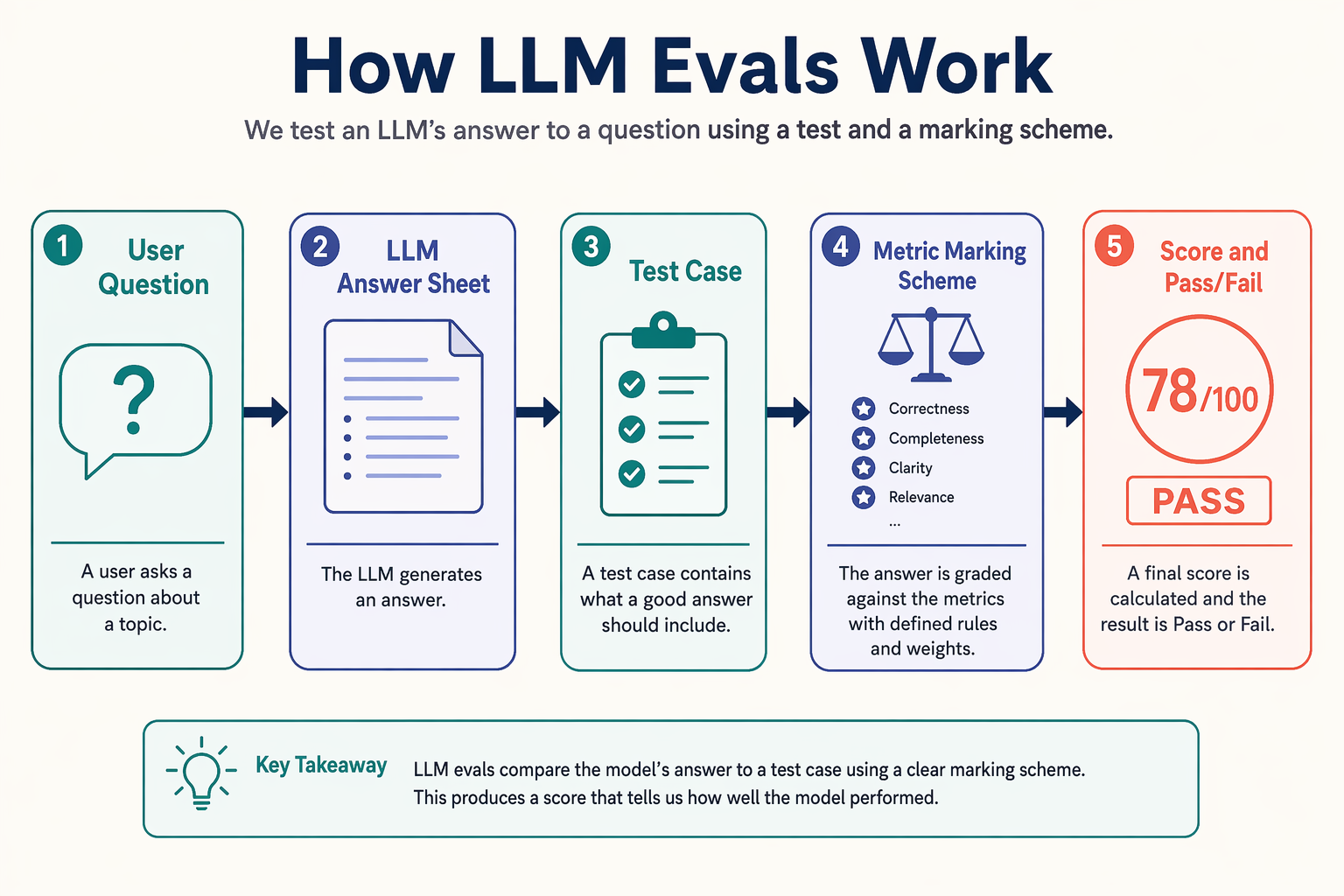
Think of an LLM app like a student in an exam hall. Every time a user asks a question, the app writes an answer. Now ask yourself: How do we know whether that answer is good? This is where evals come in.
An eval (short for evaluation) is a systematic way to check the quality of an LLM's output. In classroom language:
- LLM answer = the student's answer sheet
- Test case = the question paper plus expected answer/checking condition
- Metric = the marking scheme
- Threshold = the passing mark
This analogy is very powerful because it makes evals easy to reason about. If a student writes a beautiful answer that is still wrong, we should not give full marks. In the same way, an LLM response may sound fluent but still be incorrect, incomplete, or irrelevant.
Let us define the parts carefully:
- A test case is one example we use for checking.
For example:- Question: "What is the capital of France?"
- Expected answer: "Paris"
- A metric is the rule used to score the answer.
Example: "Does the response contain the correct fact?" - A threshold is the minimum acceptable score.
Example: "Score must be at least 0.8 to pass."
In simple Python-like form, it looks like this:
test_case = {
"input": "What is the capital of France?",
"expected": "Paris"
}
metric = "correctness"
threshold = 0.8
Now, why is manual checking not enough? Because LLM apps keep changing:
- prompts get updated
- models get replaced
- retrieval data changes
- tools and workflows change
If you check answers by hand today, that does not guarantee quality tomorrow. It is like checking only one quiz and assuming the student will always perform well in every future exam.
So evals are not just "nice-to-have." They are your repeatable exam system. They help you catch failures early, compare versions fairly, and improve your app with confidence. In engineering terms, evals bring discipline to LLM development. In classroom terms, they make sure your student is not passing by luck.
What DeepEval Gives Us
Think of DeepEval as a testing toolkit for LLM apps. If you have used pytest to test regular Python code, DeepEval feels similar in spirit - but instead of checking things like 2 + 2 == 4, it helps you check whether a language model gave a good answer.
That matters because LLM outputs are not always simply "right" or "wrong." Sometimes an answer is mostly correct, clear but incomplete, or relevant but missing evidence. DeepEval gives us a structured way to measure that.
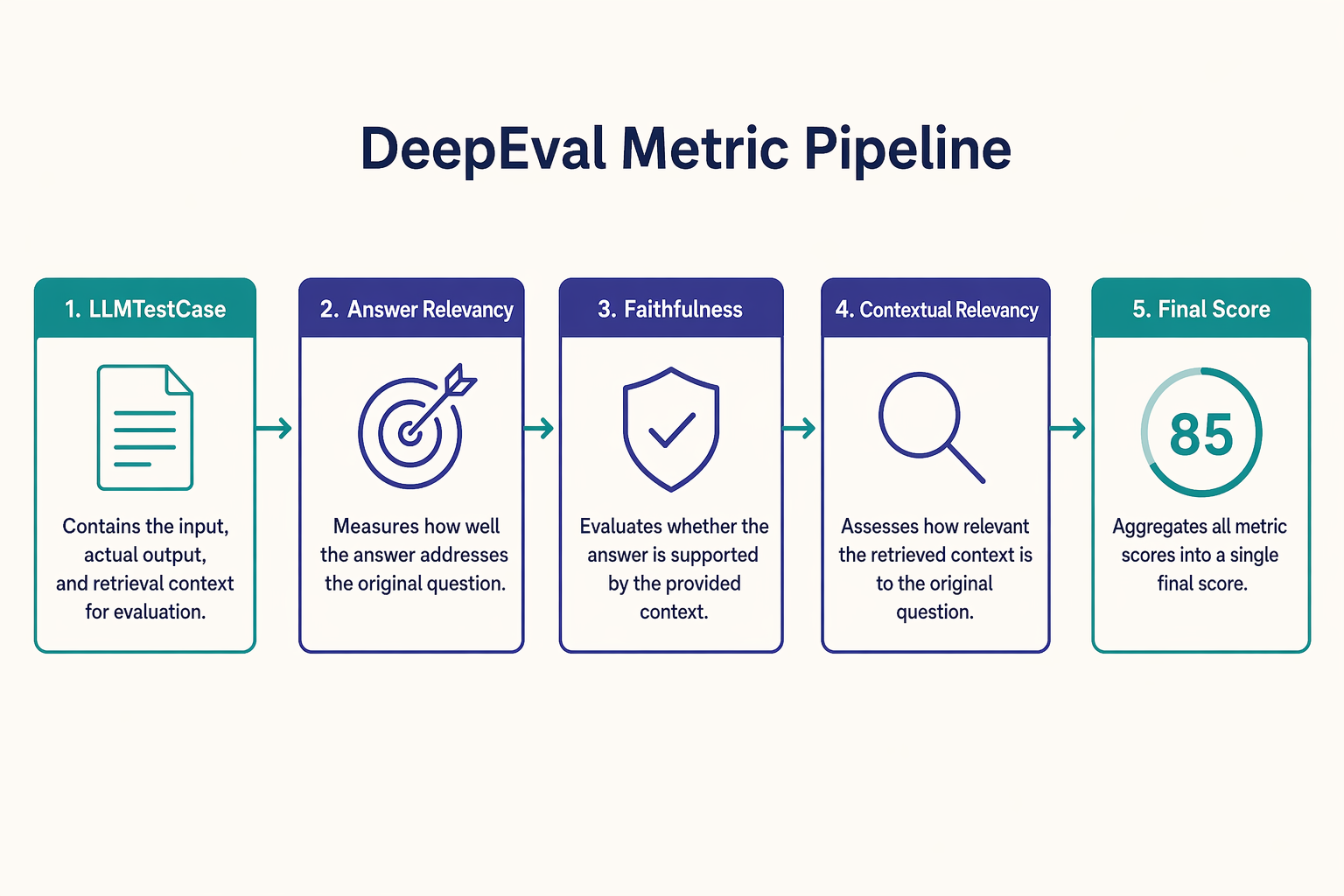
One important building block is LLMTestCase.
A test case is just one example interaction between a user and the model.
It usually includes:
input: the prompt or question given to the modelactual_output: the answer the model really producedexpected_output: the answer we hoped for, when we have oneretrieval_context: extra source material, useful in RAG apps, where the model should answer using retrieved documents
Here is a tiny example:
from deepeval.test_case import LLMTestCase
test_case = LLMTestCase(
input="What is the capital of France?",
actual_output="The capital of France is Paris.",
expected_output="Paris"
)
What each line means:
-
from deepeval.test_case import LLMTestCase
This imports the test-case class from DeepEval. -
test_case = LLMTestCase(
We create one test example. -
input="What is the capital of France?",
This is the user's question. -
actual_output="The capital of France is Paris.",
This is what the LLM answered. -
expected_output="Paris"
This is the target answer we want it to match closely.
DeepEval also uses metrics, which are like scoring rulers. A metric checks one quality, such as correctness, relevance, or faithfulness. Some of these metrics use LLM-as-a-judge, which means another LLM reads the answer and scores it using instructions. In simple terms, one model becomes the "teacher" that grades another model's response.
So, DeepEval gives us three helpful pieces:
- test cases to hold examples,
- metrics to score outputs,
- and a repeatable way to evaluate LLM behavior without guessing by hand every time.
Real Example 1: Is the Answer Relevant?
Imagine a student asks:
"What causes rainbows?"
A helpful answer would talk about sunlight, water droplets, and light bending. But what if the system replies:
"Rainbows are beautiful and often appear in paintings and poems."
That answer is related to the word "rainbow," but it does not really answer the question. This is where answer relevancy matters.
Answer relevancy means:
Does the model's answer actually match what the user asked?
In DeepEval, the AnswerRelevancyMetric checks whether the actual_output is relevant to the input.
input= the user's questionactual_output= the model's answer- threshold = the minimum score needed to "pass"
Think of it like grading a homework response. A student may write a fluent paragraph, but if it answers the wrong question, it should not get full credit.
from deepeval.test_case import LLMTestCase
from deepeval.metrics import AnswerRelevancyMetric
test_case = LLMTestCase(
input="What causes rainbows?",
actual_output="Rainbows form when sunlight passes through water droplets, bends, and splits into different colors."
)
metric = AnswerRelevancyMetric(threshold=0.7)
metric.measure(test_case)
print("Relevancy score:", metric.score)
print("Reason:", metric.reason)
print("Passed:", metric.score >= 0.7)
Here's what the important lines do:
LLMTestCase(...)creates one example to evaluate.input=stores the original question.actual_output=stores the model's real answer.AnswerRelevancyMetric(threshold=0.7)says the answer should score at least 0.7 to count as relevant.metric.measure(test_case)runs the evaluation and stores the result inside the metric object.
A high metric.score means the answer stays on-topic and responds to the question. A low score means it may be vague, off-topic, or only loosely connected.
This metric is useful because many bad answers sound good at first. Relevancy helps you check whether the answer is not just polished, but actually useful.
Real Example 2: Is the Answer Faithful to Context?
Imagine a student taking an open-notes quiz. The teacher gives them a few note cards before they answer. A faithful answer means the student uses those notes correctly and does not make up extra facts.
In a RAG system, those note cards are called retrieval_context. This is the text your app retrieved from documents before the model answered. The model's answer is usually called actual_output.
The FaithfulnessMetric checks one simple idea:
- Does the answer match the retrieved notes?
- Or did the model invent something that was never in the notes?
Here's a small example.
from deepeval.test_case import LLMTestCase
from deepeval.metrics import FaithfulnessMetric
test_case = LLMTestCase(
input="When was the Eiffel Tower completed?",
actual_output="The Eiffel Tower was completed in 1889.",
retrieval_context=[
"The Eiffel Tower is a wrought-iron lattice tower in Paris.",
"Construction of the Eiffel Tower was completed in 1889."
]
)
metric = FaithfulnessMetric(threshold=0.7)
metric.measure(test_case)
print("Faithfulness score:", metric.score)
print("Reason:", metric.reason)
What each line does:
from deepeval.test_case import LLMTestCase
Imports the test case format DeepEval uses.from deepeval.metrics import FaithfulnessMetric
Imports the metric that checks whether the answer stays grounded in the retrieved context.test_case = LLMTestCase(...)
Creates one example to evaluate.input="..."
This is the user's question.actual_output="..."
This is the model's answer.retrieval_context=[...]
These are the retrieved notes given to the model before answering.metric = FaithfulnessMetric(threshold=0.7)
Builds the faithfulness checker and sets 0.7 as the passing mark.metric.measure(test_case)
Runs the evaluation.metric.scoreandmetric.reason
Show the score and the explanation from the evaluator.
If the answer said "The Eiffel Tower was completed in 1892", faithfulness should drop, because that fact is not supported by the notes.
A related idea is contextual relevancy. This checks whether the retrieved context is relevant to the question in the first place. For example, if the question is about the Eiffel Tower but the system retrieves notes about the Great Wall of China, the context is not relevant - even if the model answers carefully. So, in RAG, you often want both: relevant context and faithful answers based on that context.
How to Think Like an Evaluator
When you evaluate an AI system, think like a good teacher checking exam answers. A good teacher does not look at only one final number and say, "Done." They ask:
- What exactly am I testing?
- What counts as a good answer?
- How much error is acceptable?
- Where and why does the system fail?
That is the evaluator mindset: clear, careful, and honest.
Start with small test cases. A test case is just one example with an input and an expected behavior. Do not begin with 500 examples. Begin with 5-10 clean ones that cover obvious situations.
test_cases = [
{"input": "What is 2 + 2?", "expected": "4"},
{"input": "Summarize: The sky is blue.", "expected": "The sky is blue."},
{"input": "Translate 'hello' to Spanish.", "expected": "hola"}
]
Next, choose the right metric. A metric is the rule used to measure quality. If you care about factual correctness, use a correctness-style metric. If you care about relevance, use a relevance metric. Do not use a fancy metric just because it sounds impressive. Use the one that matches the question.
Then set a sensible threshold. A threshold is the minimum score you will accept. If your threshold is too high, even useful outputs may fail. If it is too low, weak outputs may pass. Be practical.
Also, inspect failures manually. This is very important. A low score tells you something went wrong. Reading the actual bad output tells you what went wrong.
Keep your examples realistic. If students ask messy, incomplete, informal questions, your test set should include that. Do not test only perfect textbook inputs.
Finally, do not trust one score blindly. One number is a summary, not the truth. Always combine:
- Scores
- Real examples
- Failure analysis
- Common sense
That is how a serious evaluator works: measure carefully, inspect deeply, improve steadily.
Related Topics
Related Resources
Guardrails with langchain middleware in a finance
This blog explains how to use LangChain middleware as a guardrail layer for financial document extraction RAG systems. It covers why guardrails matter, how middleware controls retrieval and model behavior, practical validation patterns, audit-ready workflows, common failure modes, testing strategies, and when human review is required.
articleBuilding LLM memory from scratch
In LLM ,memory is one of the important ascepts of preventing halluciation and prevent contextual leaks with the LLM. This is tackled using memory attention
articleRAG Systems
The blog helps you in implementing and using RAG which is most popular LLM application