
Human-in-the-Loop AI Agents with LangChain: Architecture, Python Implementation, and Production Tradeoffs
Human-in-the-loop (HITL) is one of the most practical patterns for shipping AI agents into real business workflows. It gives teams a way to combine the speed of LLM-driven automation with the judgment, accountability, and policy awareness of a human reviewer. For engineering leaders, this matters because most production agent failures are not caused by the model being completely useless. They are caused by the model being almost right in situations where “almost” is still expensive, risky, or non-compliant.
In this article, we will look at HITL for AI agents through a real engineering lens using LangChain. We will cover what HITL means in agent systems, a practical architecture, Python example code, common implementation mistakes, and deployment concerns. The focus is not on toy demos, but on the kind of workflow you might actually build for customer support, operations, internal automation, or regulated review pipelines.
What HITL Means in AI Agents
Human-in-the-loop means the agent does not act completely autonomously for every step. Instead, specific actions are routed to a person for approval, correction, or escalation before the workflow continues.
In agent systems, HITL is most useful when the AI can generate high-quality drafts or recommendations, but a human still needs to validate the outcome before something consequential happens. Typical cases include:
- sending a refund above a threshold
- updating a CRM record that affects sales reporting
- answering a legal or medical question
- triggering external actions like deleting data or changing infrastructure
- responding to a high-value enterprise customer
The key idea is simple: let the model do the fast work, but insert a human checkpoint where risk is concentrated.
This is different from manual review of every output. A good HITL system is selective. It uses confidence signals, business rules, or action sensitivity to decide when to involve a human. That is what makes the workflow economically viable.
A Real-Life Use Case: Customer Support Agent for Refund Requests
Consider an e-commerce company building an AI support agent using LangChain. The goal is to handle refund and replacement requests automatically. The business wants lower support cost and faster resolution times, but it cannot allow the agent to issue refunds incorrectly or violate policy.
A practical workflow might look like this:
- The user asks for a refund in chat or email.
- The agent retrieves order details and return policy.
- The LLM classifies the issue and drafts a resolution.
- If the refund is below $25 and policy conditions are clear, the system auto-approves.
- If the amount is higher, the policy is ambiguous, or the sentiment is escalated, the request is sent to a human reviewer.
- The reviewer approves, edits, or rejects the agent’s proposed action.
- The final action is executed and logged.
This is a strong HITL pattern because the human is inserted exactly where business risk increases. The agent still handles most of the repetitive work: summarization, policy matching, data retrieval, and draft generation. The support team only reviews edge cases and high-impact actions.
HITL Architecture for LangChain Agents
A production HITL architecture should separate reasoning, tool use, policy gating, and human approval into distinct components. This makes the system easier to monitor and safer to evolve.
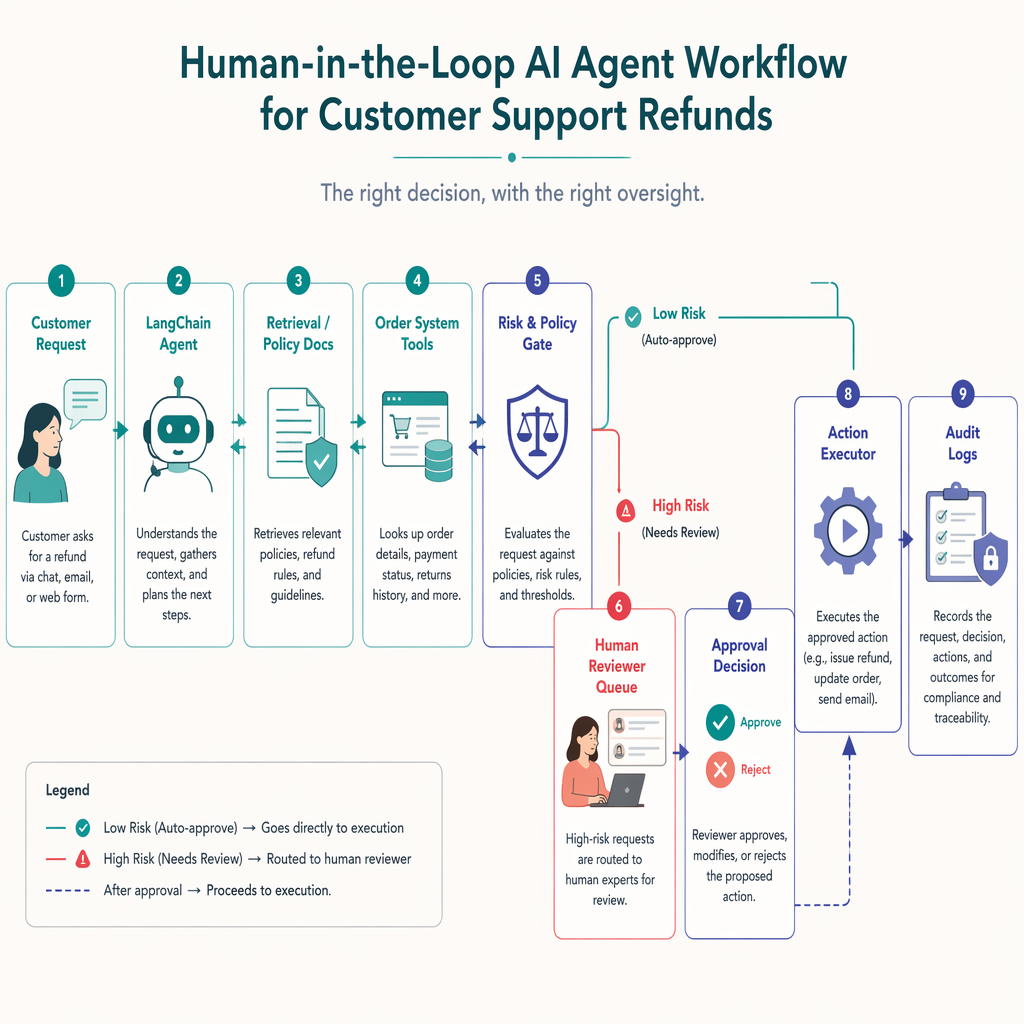
Core Components
1. Ingress Layer
This is where requests enter the system from chat, email, web forms, or internal APIs. The ingress layer should normalize input into a common schema before passing it downstream.
2. LangChain Agent
The agent orchestrates reasoning and tool calls. It can retrieve policy documents, inspect order data, classify intent, and produce a proposed action. LangChain is useful here because it provides structured model invocation, tool integration, and composable chains.
3. Retrieval and Business Context
The agent should not rely only on model memory. It needs access to:
- return and refund policies
- order history
- customer account metadata
- prior conversation context
- risk rules or thresholds
This context often determines whether the case is safe to automate.
4. Risk and Policy Gate
This is the most important HITL component. Before any action is executed, a deterministic gate evaluates:
- action type
- monetary impact
- confidence or ambiguity indicators
- policy match quality
- customer tier or legal jurisdiction
If the case is low-risk, it can proceed automatically. If not, it is routed to human review.
5. Human Review Interface
The reviewer should see more than a raw model output. They need a structured decision package:
- user request summary
- retrieved policy excerpts
- agent rationale
- proposed action
- fields that can be edited
- approve/reject/escalate controls
A good review interface reduces cognitive load and improves consistency.
6. Action Executor
Only after approval should the system call external systems, such as issuing a refund, sending a final email, or creating a support ticket.
7. Audit and Observability Layer
Every step should be logged: prompts, retrieved documents, tool calls, approval decisions, timestamps, final actions, and reviewer identity. Without this layer, debugging and compliance become painful.
The main design takeaway is that HITL should not be bolted on as an afterthought. It should be a first-class architectural boundary between model output and real-world side effects.
Data Flow and Decision Logic
A useful way to think about HITL is as a decision gate between “draft” and “execute.”
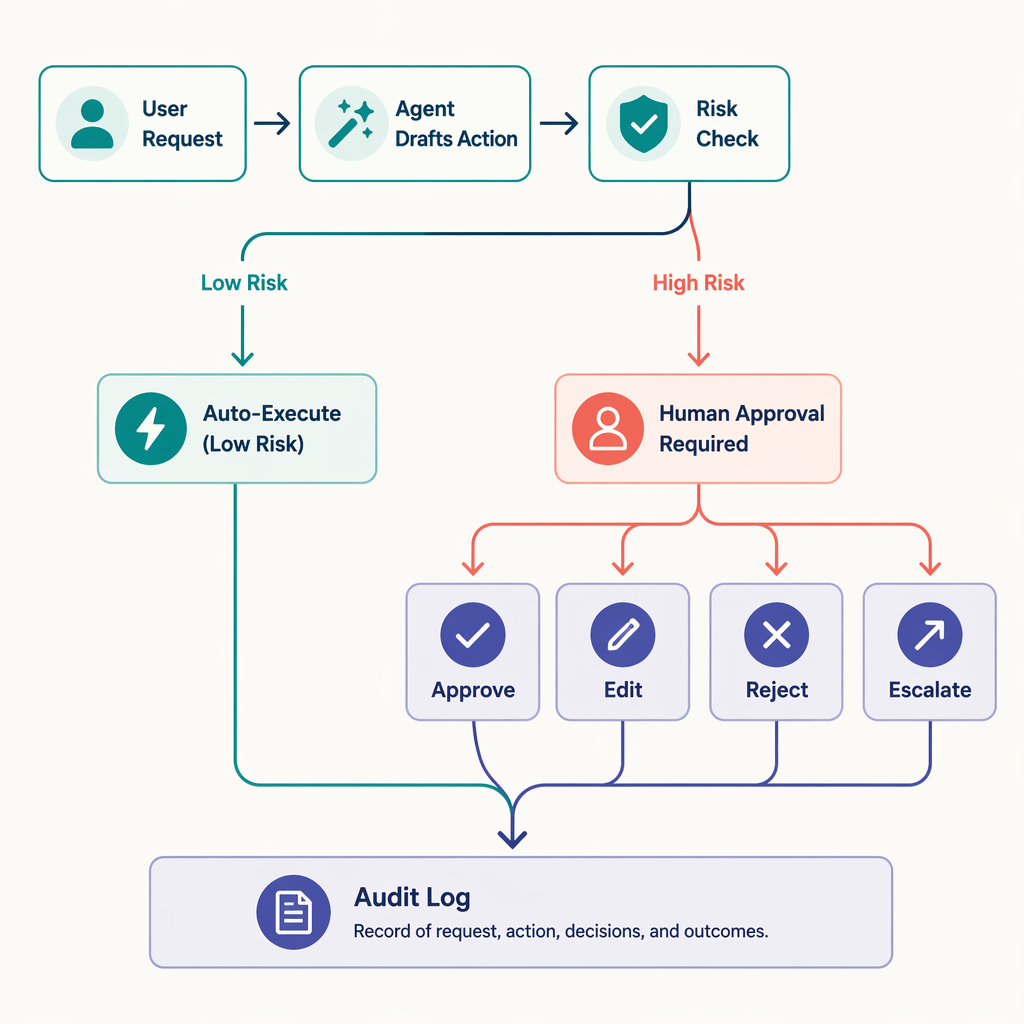
A common routing strategy combines business rules with model-derived signals. For example:
- auto-approve if refund amount is under $25, policy match is strong, and no exception keywords are present
- require review if refund exceeds threshold
- require review if the model signals uncertainty
- require review if the customer mentions fraud, legal action, injury, or repeated prior complaints
This layered logic is important because model confidence alone is not enough. In practice, explicit business rules outperform vague “confidence-based safety” when deciding whether a human should be involved.
Python Example: A Simple HITL Workflow with LangChain
The example below shows a lightweight implementation pattern. It uses LangChain to create a structured decision proposal, then applies a deterministic approval gate. The human review step is represented as a function, but in production this would be a queue plus a UI or back-office tool.
import os
from typing import Literal, Optional
from pydantic import BaseModel, Field
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
class RefundDecision(BaseModel):
action: Literal["approve_refund", "deny_refund", "request_more_info"]
amount: float = Field(description="Suggested refund amount in USD")
rationale: str = Field(description="Short explanation grounded in policy")
policy_match: Literal["strong", "medium", "weak"]
needs_human_review: bool
customer_sentiment: Literal["calm", "frustrated", "angry"]
llm = ChatOpenAI(
model="gpt-4o-mini",
temperature=0
)
structured_llm = llm.with_structured_output(RefundDecision)
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are a support operations assistant. "
"Review the request using company refund policy and order details. "
"Return a structured decision. Be conservative when policy is ambiguous."
),
(
"human",
"""
Customer message:
{customer_message}
Order details:
{order_details}
Refund policy:
{policy_text}
"""
),
]
)
def generate_refund_decision(customer_message: str, order_details: str, policy_text: str) -> RefundDecision:
chain = prompt | structured_llm
return chain.invoke(
{
"customer_message": customer_message,
"order_details": order_details,
"policy_text": policy_text,
}
)
def should_route_to_human(decision: RefundDecision) -> bool:
high_risk_keywords = ["fraud", "chargeback", "injury", "legal", "lawsuit"]
rationale_text = decision.rationale.lower()
if decision.amount > 25:
return True
if decision.policy_match != "strong":
return True
if decision.needs_human_review:
return True
if decision.customer_sentiment in {"angry", "frustrated"}:
return True
if any(keyword in rationale_text for keyword in high_risk_keywords):
return True
return False
def human_review(decision: RefundDecision) -> dict:
# In production, this would be replaced by:
# - creating a review task in a queue
# - storing the proposed action in a database
# - exposing approve/edit/reject controls in an internal UI
print("=== HUMAN REVIEW REQUIRED ===")
print(decision.model_dump_json(indent=2))
reviewer_action = input("Approve agent recommendation? (yes/no/edit): ").strip().lower()
if reviewer_action == "yes":
return {"status": "approved", "final_decision": decision}
elif reviewer_action == "edit":
edited_amount = float(input("Enter revised refund amount: ").strip())
updated = decision.model_copy(update={"amount": edited_amount})
return {"status": "approved_with_edits", "final_decision": updated}
else:
return {"status": "rejected", "final_decision": None}
def execute_action(decision: RefundDecision) -> None:
# Replace with real integration to payment or support systems
if decision.action == "approve_refund":
print(f"Refund approved for ${decision.amount:.2f}")
elif decision.action == "deny_refund":
print("Refund denied")
else:
print("Requested more information from customer")
if __name__ == "__main__":
customer_message = (
"My package arrived damaged and this is the second time I've had an issue. "
"I want a full refund immediately."
)
order_details = (
"Order #48291, delivered 3 days ago, item price $42.00, "
"customer is premium tier, prior refund count: 1"
)
policy_text = (
"Damaged items delivered within the last 30 days are eligible for refund or replacement. "
"Refunds above $25 should be reviewed by a human agent. "
"Escalate cases with repeated delivery issues or strong negative sentiment."
)
decision = generate_refund_decision(customer_message, order_details, policy_text)
print("Model decision:", decision.model_dump())
if should_route_to_human(decision):
review_result = human_review(decision)
if review_result["final_decision"] is not None:
execute_action(review_result["final_decision"])
else:
print("No action executed.")
else:
execute_action(decision)
What This Example Gets Right
This pattern is intentionally simple, but it captures several production-friendly ideas:
- the model produces a structured output instead of free-form text
- deterministic rules decide whether a human is needed
- execution is separated from reasoning
- human approval happens before side effects
- the result can be audited and extended
The most important line is with_structured_output(RefundDecision). This turns the LLM into a predictable decision generator with fields your system can validate. That is far safer than trying to parse arbitrary prose after the fact.
The second key design choice is that should_route_to_human() does not trust the model alone. It combines the model’s own review recommendation with explicit business rules.
Architecture Decisions and Tradeoffs
HITL improves safety and reliability, but it adds system complexity. The right design depends on your business constraints.
Synchronous vs Asynchronous Review
A synchronous review flow blocks the user until a human approves the result. This is suitable for internal tools, low-volume workflows, or premium support channels. The downside is latency.
An asynchronous flow creates a review task and notifies the user that the request is under review. This is better for high-volume support or back-office processing, but it requires queueing, state management, and notification handling.
Full Review vs Risk-Based Review
Reviewing every case is easy to reason about, but it destroys the efficiency benefits of an agent. Risk-based review is more scalable, but it requires careful threshold design and monitoring.
Human Editing vs Human Approval Only
Some teams only let humans approve or reject an AI recommendation. Others allow editing. Editing improves flexibility, but it can make audit trails and consistency harder unless the final decision is tracked clearly.
Model-Centric vs Rule-Centric Gating
A model-centric gate might ask the LLM whether confidence is low. A rule-centric gate uses thresholds and deterministic logic. In most production systems, a hybrid works best, but if you must choose, rule-centric gating is easier to test and defend.
Here is a concise comparison:
| Design choice | Option A | Option B | Practical tradeoff |
|---|---|---|---|
| Review timing | Synchronous | Asynchronous | Synchronous is simpler; asynchronous scales better |
| Review scope | All actions | Risk-based actions | Risk-based preserves ROI but needs better policy logic |
| Reviewer control | Approve/reject | Approve/edit/reject | Editing is flexible but complicates governance |
| Gate style | Model-driven | Rule-driven | Rules are more auditable; models catch nuance |
The takeaway is that HITL is not just a safety feature. It is an operational design problem. Your review queue, latency budget, and compliance needs shape the right implementation.
Deployment Concerns in Production
Many HITL demos stop at the approval button. Real systems need more operational maturity.
State Management
Agent workflows often span multiple steps and multiple systems. You need to persist:
- conversation state
- retrieved evidence
- model outputs
- pending review status
- reviewer decisions
- final execution result
Without persisted state, retries and recovery become brittle.
Queueing and SLAs
If humans are part of the workflow, your system now has queue dynamics. A surge in requests can create review backlogs. That means you should define:
- review priority rules
- maximum wait times
- escalation paths
- fallback behavior if no reviewer is available
Auditability
In regulated or customer-facing environments, you need to answer questions like:
- Why was this action taken?
- Which policy text was used?
- What did the model recommend?
- Who approved the final action?
This is why structured outputs and event logs matter so much.
Security and Access Control
Human reviewers should only see the minimum necessary customer data. If you expose a review UI, you also need role-based access control, action logging, and secure storage of sensitive content.
Evaluation and Drift Monitoring
Your review rate is itself a useful metric. If the percentage of cases requiring review suddenly spikes, something changed: model behavior, policy retrieval quality, incoming case mix, or a downstream system.
Useful operational metrics include:
- auto-approval rate
- human override rate
- average review latency
- reviewer agreement rate
- execution failure rate after approval
- customer satisfaction by path
These metrics tell you whether HITL is helping or merely masking weak automation.
Common Mistakes When Building HITL Agents
Mistake 1: Treating HITL as a Manual Patch
Some teams add human review only after bad outcomes occur. This leads to messy control points and inconsistent approval logic. HITL should be designed into the workflow from the beginning, especially around external actions.
Mistake 2: Letting the Model Execute Before Approval
The agent should not perform irreversible actions and then ask for confirmation afterward. The approval gate must sit before the side effect.
Mistake 3: Using Only Model Confidence
LLM confidence is not a reliable sole signal for risk. High-confidence mistakes happen. Always combine model output with explicit business rules.
Mistake 4: Giving Reviewers Too Little Context
If the reviewer only sees the final answer, they cannot judge whether the agent used the right evidence. Show policy excerpts, retrieved facts, and the proposed rationale.
Mistake 5: Ignoring Reviewer Experience
A slow or confusing reviewer interface causes bottlenecks. The human part of HITL is still product design. If review takes too long, your automation ROI collapses.
Mistake 6: Failing to Learn from Reviews
Human review is not just a safety net. It is a data asset. Reviewer edits and rejections should feed back into prompt improvements, policy tuning, routing logic, and evaluation datasets.
The practical lesson is that HITL works best when it is both a control mechanism and a learning mechanism.
Where LangChain Fits Well
LangChain is useful in HITL systems because it helps structure the agentic part of the workflow:
- prompt composition for decision generation
- tool calling for retrieving order or policy context
- structured outputs for predictable schemas
- chain composition for reusable workflow steps
- integration with broader application logic
What LangChain does not replace is your business control plane. You still need application-layer logic for queueing, approval routing, persistence, observability, and security. That separation is healthy. Agent frameworks are best used for orchestration and reasoning, not as a substitute for production workflow design.
Conclusion
HITL is one of the most effective ways to make AI agents useful in real products without overexposing the business to model errors. In a LangChain-based system, the winning pattern is straightforward: let the agent gather context and draft a structured action, route risky cases through deterministic approval logic, involve a human before real-world side effects, and log everything.
If you build HITL this way, you get more than a safety net. You get a practical operating model for deploying AI agents where speed and judgment need to coexist.
Related Topics
Related Resources
Building LLM memory from scratch
In LLM ,memory is one of the important ascepts of preventing halluciation and prevent contextual leaks with the LLM. This is tackled using memory attention
articleRAG Systems
The blog helps you in implementing and using RAG which is most popular LLM application
articleAgentic AI - Complete Guide
The blog gives you complete inderstanding of AI Agents